確定申告書のPDFを集計する方法
e-taxで確定申告した後、保存用のデータをPDFでダウンロードすると思いますが、この様式を活用して累計の納税額や社会保険料、あるいは収入額の累計を集計したいと思います。
この方法についてですが、当初は単純に「申告納税額」などの文字列をPythonの正規表現で検索し、その数字のみを取り出して各年度で集計すればいいと考えたのですが、PDFは縦、横で文字列が並びますし、改行などもあって特定は困難と感じました。
他にもcsvで出力した後に集計したり、あるいは画像でキャプチャした後に数字を読み込む方法も試してみましたが、画像には枠線なども映るため、精度が低い結果となりました。
結論としましては、納税額などの各項目の座標を特定した上で、その範囲の数字を取り出したのちに集計するのが一番うまくいくと思います。
確定申告書のPDFからPythonでデータを抽出
まず、サンプルとして、既存の確定申告書のPDFから取り出したい箇所の数字をピックアップし、その箇所の座標を特定します。
例えば、確定申告書の納税額に40152356円とあった場合、各年度のPDFからこの箇所の数字を抜き出して集計すれば、累計の合計納税額が判明することになります。
ちなみに、こちらはサンプルとして年収1億円で出力しただけですので、当サイト運営者が4000万円納税しているというわけではないです。

このターゲットの箇所の座標を特定するには以下のようにします。
import fitz
# PDFファイルを開く
pdf_file = fitz.open('your.pdf')
# 特定のページを取得
page_number = 1 # 0が最初のページ
page = pdf_file[page_number]
# 特定の文字列の座標を取得
search_text = '4 0 1 5 2 3 5 6'
results = page.search_for(search_text)
# 結果を出力
for result in results:
print(f"Character '{search_text}' found at: {result}")このPDFの処理にはPythonのPyMuPDFのライブラリがおすすめです。他のライブラリの場合、年度によってはCID問題が発生してしまい、文字を正常に表示できなくなるため、当サイト運営者が試した限りはPyMuPDFが一番うまくいくと感じました。
このfitzはPyMuPDFのことですが、pipでインストールできます。
pip install pymupdf確定申告書は1マスに1文字なので、半角スペースを入れて検索するとよいでしょう。この辺りは生成AIにコードを書いてもらえば簡単です。
そうしますと、この箇所の座標は以下のように表示されます。
Character '4 0 1 5 2 3 5 6' found at: Rect(432.20001220703125, 344.53436279296875, 537.1334228515625, 360.23748779296875)端数を切り上げますと、ざっくりRect(433, 345, 538, 361)の範囲がPDFの納税額の箇所に該当することになり、左上が(433,345)で左から433ポイント、上から345ポイントの箇所、右下が(538.361)の領域になります。つまり、幅が105ポイント、高さが16ポイントの範囲になります。
今後は逆に、各PDFのこの領域の値をループしながら順番に取得し、半角スペースをリプレイスで除去したのち、年度ごとに並べて集計すれば、累計の合計額が判明します。
■納税額の領域=Rect(433, 345, 538, 361)
この方法を応用すれば、社会保険料控除や給与の箇所など、すべての項目について、座標の範囲を特定することができるはずです。
■社会保険料控除=Rect(ほにゃらら)
ただし、実際には年度や様式によって座標が異なり、かなりバラバラだったため、上記の領域ではヒットしない年度などもありました。
そのため、以下のような手順で確認するとうまくいくと思います。
①まずは各PDFにて「45」などの箇所を特定したのち、その座標を確認する
②各PDFのその座標にて、その数字の有無を確認することでどの様式なのかを特定する
③その様式での納税額の箇所の座標から値を取得する
最終的には、以下のようなコードになりました。
import fitz
# 対象のPDFファイルリスト
pdf_files = ['平成何年.pdf', '令和何年.pdf','令和何年.pdf']
# 条件に対応する座標範囲と取得する座標範囲を定義
cond_rects = [
fitz.Rect(394, 364, 401, 373),
fitz.Rect(402, 372, 410, 381),
fitz.Rect(434, 383, 442, 391),
fitz.Rect(391, 380, 399, 389),
fitz.Rect(394, 336, 403, 346),
fitz.Rect(400, 348, 408, 359)
]
target_rects = [
fitz.Rect(430, 360, 532, 376),
fitz.Rect(440, 369, 540, 385),
fitz.Rect(460, 381, 561, 391),
fitz.Rect(430, 377, 529, 393),
fitz.Rect(430, 336, 529, 346),
fitz.Rect(430, 347, 538, 363)
]
# 合計値を格納する変数
total = 0
# PDFファイルごとに処理を実行
for pdf_file_path in pdf_files:
pdf_file = fitz.open(pdf_file_path)
# ページ番号が0または1のページを対象にする
for page_number in range(2):
page = pdf_file[page_number]
for i, cond_rect in enumerate(cond_rects):
# 条件に合致するテキストを取得
search_text = "43" if i == 0 else "42" if i in [1, 2, 3] else "45"
results = page.search_for(search_text)
found = any(cond_rect.intersects(r) for r in results)
if found:
# 対象の座標範囲内のテキストを取得
text = page.get_text('text', clip=target_rects[i])
# 半角スペースとカンマを除去
text = text.replace(' ', '').replace(',', '')
# 各数字を合計
for num in text.split():
total += int(num)
# 結果を出力
print(f"File: {pdf_file_path}, Page: {page_number + 1}, Text: {text}")
# ファイルを閉じる
pdf_file.close()
# 合計値を表示
print(f"Total: {total}")こちらは架空のデータですが、こんな感じで集計されるかもしれません。
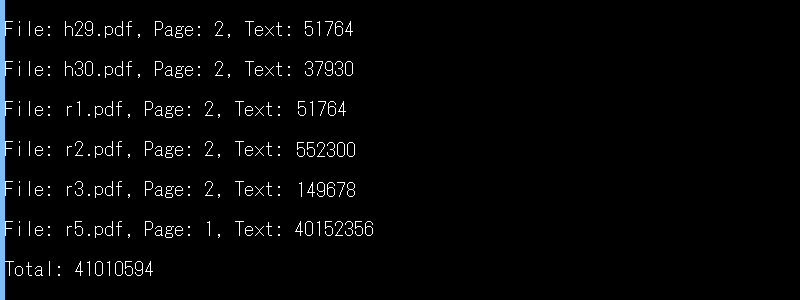
上記の座標については、当サイト運営者のケースではうまくいきましたが、各様式を漏れなく詳細にチェックしたわけではないため、様式によっては機能しないかもしれません。
様式の判別については、人工知能の機械学習でパターン認識をすることで判別できる気もしますが、上記のような方法でも判別は可能だと思います。
ちなみに、手書きで入力した確定申告書については、スキャンするなりして画像から読み込む以外に方法がないと思いますが、枠線や背景などがある画像の場合、それを「国」などの四角い系の漢字と誤って判別してしまったりするため、うまくいかないと感じました。
画像ではなく、テキストとしてPDFを処理することをおすすめします。